每经编辑 孙志成

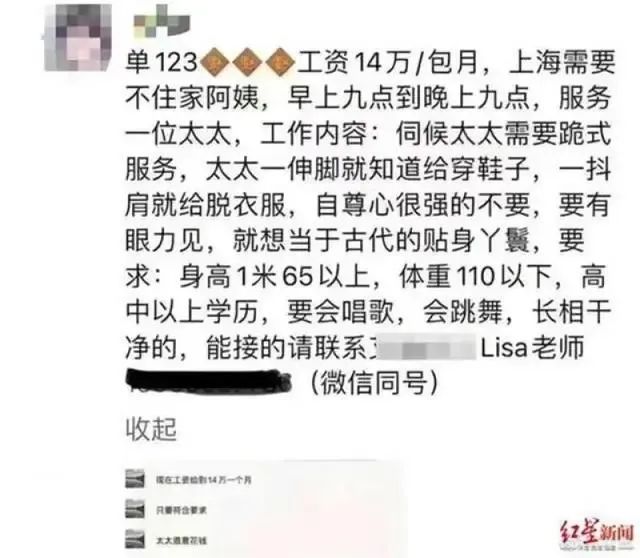
工资14万/包月
“伺候太太需要跪式服务”
“自尊心很强的不要”
“相当于古代的贴身丫鬟”
……
近日,一则用离谱的要求、天价薪资招聘保姆的新闻,引起了网友们的热议。
网传内容显示,14万月薪所招聘的为不住家保姆,工作时间从早9点到晚9点,服务内容包括给“上海太太”穿鞋、脱衣服等内容,且要求提供“跪地服务”。还要求保姆身高需达到1米65以上,体重在110斤以下,高中以上学历,会唱歌跳舞长相干净……
最近,这起事件出现了反转。
5月19日,据澎湃新闻报道,从上海闵行区市场监督管理局获悉,近日,有媒体报道家政公司“14万月薪招聘跪式保姆”,目前闵行区市场监督管理局已对当事人上海今巢家政服务有限公司涉嫌虚假宣传的行为进行立案调查。

家政公司负责人:
雇主提出侮辱性极强的要求
据红星新闻5月13日报道,记者联系网传图中的家政公司,对方表示该招聘信息属实。网传图片中的“中间人”Lisa则表示:“这名客户已经以14万月薪招聘到2位保姆。”
对于网传内容中是否存在“跪地服务”的说法,上述家政公司并未给予正面回应,但这一要求却惹来不少网友的争议。有网友也质疑该招聘信息的真实性,认为这些可能是家政公司的营销噱头。
5月17日,据上海电视台《新闻坊》报道,该栏目记者以客户找保姆的名义致电了上海今巢家政服务有限公司,接电话的业务员李女士却表示:“(14万月薪招保姆)那只是客户娱乐性的东西,她可能就拿我们公司开涮。”
随后,记者查到涉事家政公司的办公室,位于闵行区吴泾镇的公司本部,并公开了身份。
一位公司负责人证实,实际上“14万月薪招聘的保姆”并没有找到,此前只是业务员误把暗访的记者当成雇主,为了“面子”而作出的回应。
这位负责人表示,之所以对外宣称“找到了保姆”,实际上也是因为这则“14万月薪招聘跪式保姆”的广告,让他们公司深受其扰。
据《新闻坊》报道,公司负责人私下表示,这位雇主真实动机的确让人存疑,因为“她”甚至要求应聘者先行提供一段让人“倍感屈辱”的视频,里面甚至还要应聘者口称“奴婢”等。
客户这些侮辱性极强的要求提出后,这家涉事家政公司就立刻中止了服务。
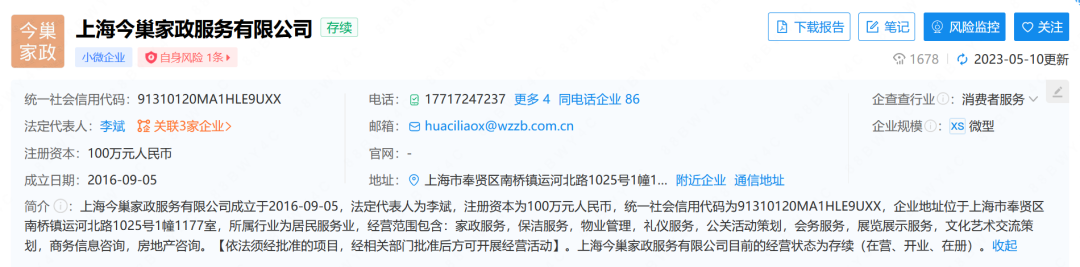
企查查显示,上海今巢家政服务有限公司成立于2016年,法定代表人为李斌。
家政公司虚假宣传被严查
专家:要维护从业者基本权利
此前,2021年,上海一家家政公司公布在社交平台上的求职信息引发了多方关注。在求职者信息中,学历那一栏上赫然写着“清华毕业”,还贴了一张清纯美女的照片。

彼时,此事引发网上热烈讨论。之后,该公司因“虚假或者引人误解的商业宣传”被上海松江区市监局处以罚款20万元,而上述宣传信息均为虚构。
对于这则“14万元招聘跪式保姆”的新闻,有网友指出,要求保姆跪地服务,有辱家政从业者的人格尊严;也有网友直言,作为中介的家政公司,也应在审核从业者资质的同时,对雇主部分不合理要求进行审核,争取双方的平等和互相尊重。
如今,这起招聘也涉嫌虚假宣传,市场监管部门已经启动调查。但即便招聘属实,其所要求的这种践踏尊严的做法,市场监管部门也应查明真相,以正视听。
上海自2020年5月1日开始施行的《上海市家政服务条例》中,总则第3条明确:家政服务活动应当遵循自愿平等、诚实守信、安全便民的原则;家政服务业的管理应当遵循促进行业发展、监管和服务相结合、平等保护各方合法权益的原则。
据红星新闻报道,成都市家政服务行业协会会长王小兵介绍,行业内提供主流家政服务的价格相差并不大,如月嫂的月薪大概在15000元左右、育儿嫂月薪在万元上下,而普通家政员工月薪约6000元。
王小兵认为:“无论是要求帮忙换鞋脱鞋,还是要求提前在家门等待,行业内认为,只要未涉及违法要求和明显的侵权行为,那么雇主和从业者更多是双向选择,如果从业者不介意也无可厚非。”
王小兵也同时指出,站在保护从业者权益的角度来说,雇主的任何要求都应写入合同之中,从业者事先也有知情权:“如果服务过程中额外增加需求,或者出现违法或违背道德底线的需求,那么无论中介还是从业者,都有权终止服务。”
王小兵也呼吁,家政中介机构应当在做好从业者审查筛选的同时,也为其权益保护提供保障,如遇非合理合法诉求,也应站在从业者角度出发,与雇主进行协商,维护从业者基本权利。
值得注意的是,5月18日,杭州女童电梯坠亡案一审宣判:保姆被判一年缓刑两年,但家属表示“坚决不能接受”,一定会上诉。女童父亲表示,保姆吴某某月薪8000元,家政公司当时称她有高级母婴护理师证书,“因为她有证,我才放心把孩子交给她带,后来才知道这个‘证书’花钱可以买到,后续会追究家政公司的民事责任。”相比家政公司在宣传上的不遗余力,它们更应该将重点放在服务的质量上,而不是在制造噱头、抢市场份额上。
编辑|孙志成 杜恒峰
校对|王月龙
封面图自视觉中国(图文无关)
每日经济新闻综合新闻坊、澎湃新闻、红星新闻等









51区外星人真相:美国51区在哪?里面真的有18个外星人吗?